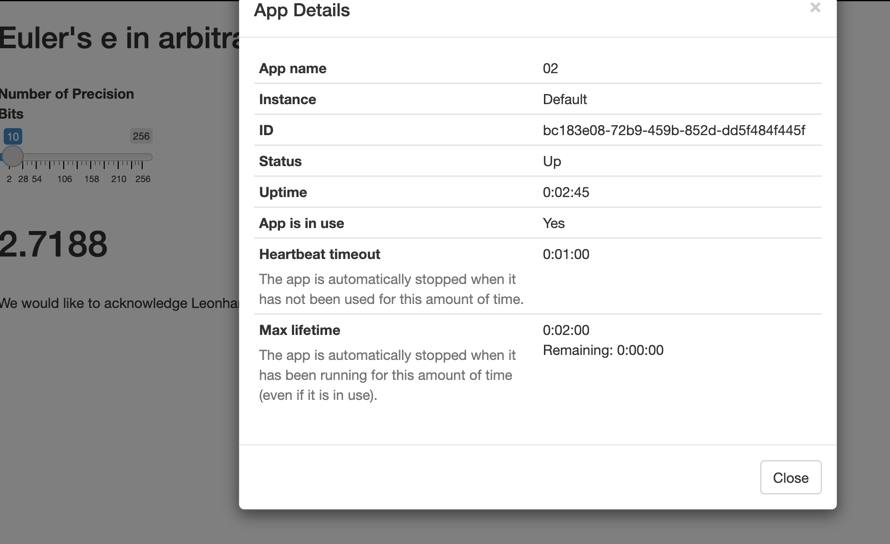
In a k8s env with app recovery via redis, I can’t get max-lifetime in an app to be effective.
I.e. even when the value is set and the countdown is over, the app continues running and is responsive.
Is this expected? I couldn’t find any hint in the docs about this behavior.
Yes, this works in k8s as well. However, ShinyProxy only checks the lifetime of apps every 5 minutes. Therefore, the exact time at which an app is stopped, can be a few minutes longer than what’s defined in the configuration.
We’ll update the documentation to better explain this.
Indeed there is no setting to change the interval. The idea is that the max-lifetime setting is usually at least one hour or more, and therefore it doesn’t matter that it takes a few minutes longer before the app is stopped.
Is there any reason you want to have a short max-lifetime or that you want it to be more precise?
I was just doing some testing and hence trying with low values.
Indeed, in a specific use case I would want to set it to 24h, so a fresh pod is started once a day (at least).
However, I see that there might be edge cases where this isn’t perfect and might lead to a termination during peak hours when a user is actively using the pod. I think I should likely use the new API endpoint to stop the delegate proxy at a controlled time in non-peak hours/during the night.
Note that this setting only applies to the app that is owned by the user. In the context of pre-initialized containers, we call this a DelegatingProxy, the underlying container is the DelegateProxy. The lifetime setting only applies to the DelegatingProxy and will not influence the lifetime of the underlying container. So unless you are using allow-container-re-use: false, the underlying container will not be stopped when the DelegatingProxy reaches its max lifetime.
That being said, we do want to implement a setting for a max lifetime of the DelegateProxy. We plan to do this in the next release, if you need this urgently, feel free to contact us and we can check to work on this.
With all these interplays and options in place: what is the most straightforward approach to achieve a scheduled daily refresh of an app?
I want the app to restart right after its pod got removed, so it is “ready” to use for the next incoming request. With all the options I’ve tried so far, the app pod isn’t automatically coming up again. I first need to launch the app, run into a “crash”, and then wait for SP to spawn a need container.
In addition, I was experimenting with a cron job which nudges the app URL and triggers it non-interactively right after it got terminated, but this feels like I might be overcomplicating the task and there must be a simpler solution.
Removing or killing the pods outside ShinyProxy will always cause some issues. Currently ShinyProxy does not actively monitor the pods, but even if this was implemented, removing the pods manually will cause issues (because there will always be a delay for ShinyProxy to detect this).
As you mentioned before, the API is the best way to restart the pool of containers, see Swagger UI
The API will take care of gracefully stopping the old pods (and only if nobody is actively using them) and creating new pods.
Currently this requires you to authenticate as an admin user using the regular authentication method of ShinyProxy. We want to improve this, such that there is a dedicated authentication method for the admin API.
Another option we would like to implement is to have either a max lifetime for containers or to be able to schedule a full restart of the pool.
Currently ShinyProxy does not actively monitor the pods, but even if this was implemented, removing the pods manually will cause issues (because there will always be a delay for ShinyProxy to detect this).
That’s very interesting to hear about. I wonder if that could be improvements to this.
Especially for teams transitioning from Posit Connect, this feels like a downside, as there the lifetime of app pods are checked/tracked in live speed and removing/deleting one will automatically trigger a respawn of such (if the min setting for an app is active).
I’ve understood that the operator isn’t watching the app pods but only the shinyproxy instances. However, I wonder if these could also gain a similar “live watch” behaviour to account for this.
Another option we would like to implement is to have either a max lifetime for containers or to be able to schedule a full restart of the pool.